本篇會以大數據(攝取資料)來做為介紹,對於本人來說即是使用python 來做於大數據收集所以大多資訊會以python為主。
Python 現在很夯的語言,因為它具有GOOGLE後台的AI資源以及模組化的各項設計,加上語法非常貼近我們日常使用,所以變成大眾化的程式語言。
攝取資料:
對於攝取資料方式,大多都以網路來說,對於網路攝取資料方式,相信大家都不陌生,即是使用網路爬蟲來解決,分析HTML資料後再藉由爬蟲模組化功能將HTML相對應資料擷取下來做使用。
相信有用過python的人,多少都知道Jupyter notebook,此工具適合拿來做大數據使用,因為背景是以網頁架構設計,所以攝取下來的資料都非常完整以及工整,若是一般的IDE可能沒有他這麼的方便,再來IDE決定清楚之後再來針對爬蟲所需要的資料來使用對應的模組,request 以及 beautifulsoup4,這兩個非常常見在使用網路爬蟲上,這兩個部份一個是針對網路性質抓取對應HTML資料下來(request),另外一個即是將HTML資料做解析並且抓取想知道的資料(beautifulsoup4)
import request
from bs4 import BeautifulSoup
url = "輸入您要的網址"
html = request.get(url)
print (html.text)
以上小段的程式碼,此示範為將一個所需要的網站內容透過python內部的request方式抓下來並且收錄到自己的參數中,後續可以針對網頁的特性關西可以使用beautifulsoup4方法來抓取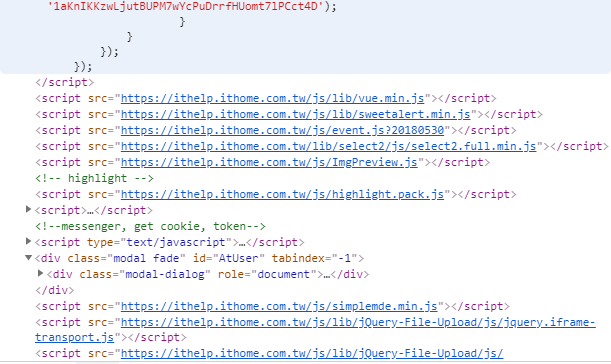
根據圖片中的 class為主 以及 id 利用beautifulsoup4 抓取只要注意一般的標籤名子 a t div 等等 都是一般標籤名,如果遇到類別 class 以及 特殊名子 id 需要用對應方法
class => soup.select('.modal-dialog')
id => soup.select('#AtUser')
這樣以上介紹即可做到想到抓到的相關資料,以上為不專業介紹,請各位海涵,後段會再介紹細節部分,那我們下篇見~

